Learning to grasp - Jacob Varley 인공지능로봇/인공지능2018. 11. 13. 10:40
Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences - Columbia University, 2018
Abstract
Providing robots with the ability to grasp objects has, despite of research, remained a challenging problem. The problem is approachable in constrained environments where there is ample prior knowledge of the scene and objects that will be manipulated. The challenge is in building systems that scale beyond specific situational instances and gracefully operate in novel condition. In the past, heuristic and simple rule based strategies were used to accomplish tasks such as scene segmentation or reasoning about occlusion. These heuristic strategies work in constrained environments where a roboticist can make simplifying assumptions about everything from the geometries of the objects to be interacted with, level of clutter, camera position, lighting, and a myriad of other relevant variables. With these assumptions in place, it becomes tractable for a roboticist to hardcode desired behavior and build a robotic system capable of completing repetitive tasks. These hardcoded behavior will quickly fail if the assumptions about the environment are invalidated. In this thesis, we will demonstrate how a robust grasping system can be built that is capable of operating under a more variable set of conditions without requiring significant engineering of behavior by a roboticist.
This robustness is enabled by a new found ability to empower novel machine learning techniques with massive amounts of synthetic training data. The ability of simulators to create realistic sensory data enables the generation of massive corpora of labeled training data for various grasping related tasks. The use of simulation allows for the creation of a wide variety of environments and experiences exposing the robotic system to a large number of scenarios before ever operating in the real world. This thesis demonstrates that it is now possible to build systems that work in the real world trained using deep learning on synthetic data. The sheer volume of data that can be produced via simulation enables the use of powerful deep learning techniques whose performance scales with the amount of data available. This thesis will explore how deep learning and other techniques can be used to encode these massive datasets for efficient runtime use. The ability to train and test of synthetic data allows for quick iterative development of new perception, planning and grasp execution algorithms that work in a large number of environments. Creative applications of machine learning and massive synthetic datasets are allowing robotic systems to learn skills, and move beyond repetitive hardcoded tasks.
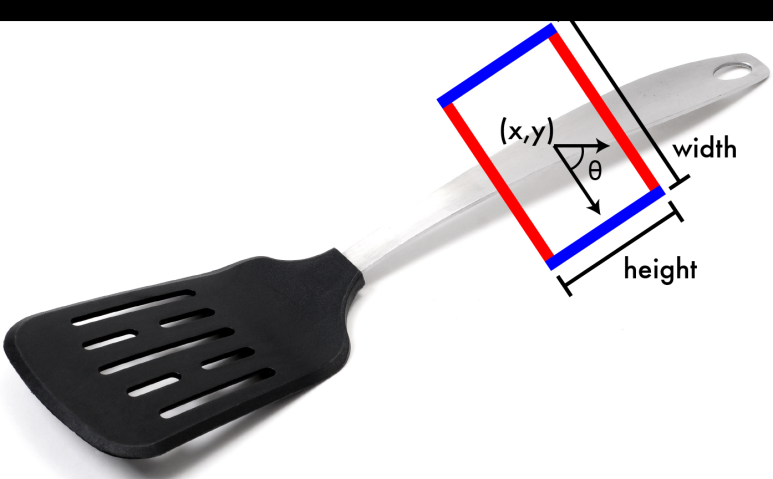
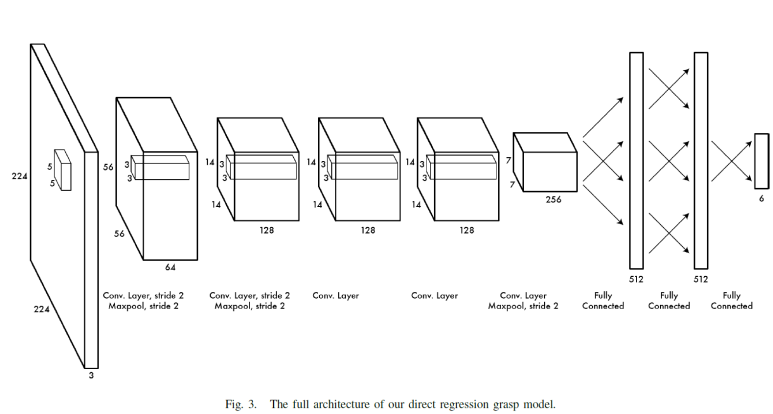
일단 이논문은 파지작업과 CNN을 결합한 것으로 보인다. RL기반은 아닌 것이다. 특이한 것은 에너지 최적화를 주제삼은 것이다. 잡는냐 못잡는냐보다 접촉에너지를 최소화하는게 왜 중요한 문제인지 이해가 안간다. Heatmap이 신경망의 최종출력인데, 손바닥의 터치 등고선을 고려한 것일까. 키워드는 포인트 클라우드, RGBD 키넥트센서,
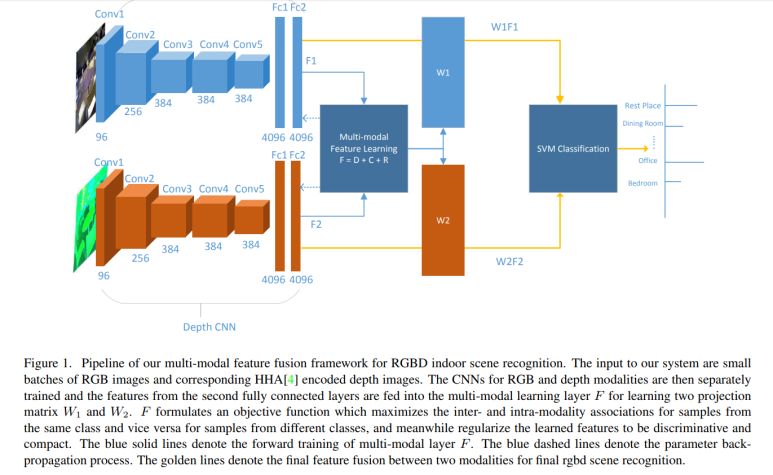
일단 우리의 작업을 위해 일단 물체를 환경으로 부터 분리하는 Semantic map을 구성하는 능력이 필요하다. 이는 RGB영상처리에서 RGBD영상처리에 대한 연구가 필요한 것이다.