RGBD Object labeling using CNN 인공지능로봇/로봇손지능2018. 11. 13. 10:39
U. Asif, M. Bennamoun, and F. Sohel, “A Multi-modal, discriminative and spatially invariant CNN for RGB-D object labeling,” IEEE Transactions on Pattern Analysis and Machine Intelligence
Abstract
While deep convolutional neural networks have shown a remarkable success in image classification, the problems of inter-class similarities, intra-class variances, the effective combination of multimodal data, and the spatial variability in images of objects remain to be major challenges. To address these problems, this paper proposes a novel framework to learn a discriminative and spatially invariant classification model for object and indoor scene recognition using multimodal RGB-D imagery. This is achieved through three postulates: 1) spatial invariance - this is achieved by combining a spatial transformer network with a deep convolutional neural network to learn features which are invariant to spatial translations, rotations, and scale changes, 2) high discriminative capability - this is achieved by introducing Fisher encoding within the CNN architecture to learn features which have small inter-class similarities and large intra-class compactness, and 3) multimodal hierarchical fusion - this is achieved through the regularization of semantic segmentation to a multi-modal CNN architecture, where class probabilities are estimated at different hierarchical levels (i.e., imageand pixel-levels), and fused into a Conditional Random Field (CRF)- based inference hypothesis, the optimization of which produces consistent class labels in RGB-D images. Extensive experimental evaluations on RGB-D object and scene datasets, and live video streams (acquired from Kinect) show that our framework produces superior object and scene classification results compared to the state-of-the-art methods.
일단 CNN과 RL을 떠나, Grasping Object를 위해 일단 필요한 것은 3D object에 대한 perception이다. robotics에서 가장 중요한 것은 일단 실제 환경을 보고 인식하는 거이므로 일단 2D이미지가 아닌 3D이미지 인것이다. 즉 RGB-D와 같은 3차원 이미지 정보를 인식하여 물체를 인식하는 문제이다. 2번째는 단순히 물체의 분류뿐아니라 3차원 위치, 방향정보를 인식해 내는 것이다. 이 문제만으로도 아직 많은 연구가 진행중인 것을 알 수 있다. 이 논문만 해도 공간불변(이동, 회전. 스케일 등) 신경망을 별도 기존의 CNN과 결합시켜 조합적으로 사용했다고 기술하고, 멀티모달 계층적 퓨전을 위해 멀티모달 CNN구조를 제안하고 있다. 또한 fisher encoding이란 기법을 적용하여, 분류유사성을 다루고 있다. 실제로 라이브 비디오를 통해, 기존의 방법보다 뛰어난 결과를 보여주고 있다.
이뿐 아니다.저자의 최근 연구 비디오를 보면, Graspnet을 보여주고 있다.
GraspNet: An Efficient Convolutional Neural Network for Real-time Grasp Detection for Low-powered Devices Umar Asif, Jianbin Tang, and Stefan Harrer, IBM Research Australia, IJCAI - 2018
좀 더 논문을 살펴보면, RGBD이미지를 위해 멀티모달을 위한 CNN구조를 보면 RGB를 위한 CNN들과 depth모달리티를 위한 CNN이 분리되어 학습되고, 두번째 FCN으로 연결되는 구조를 보인다.
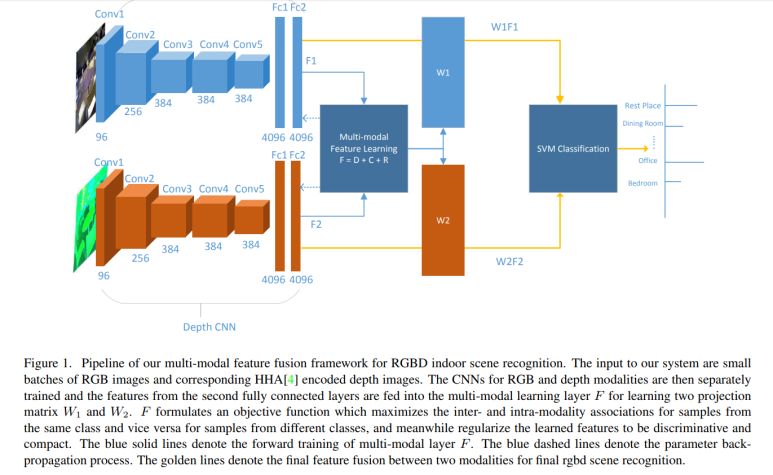
[PDF]Discriminative Multi-Modal Feature Fusion for RGBD Indoor Scene .
'인공지능로봇 > 로봇손지능' 카테고리의 다른 글
| Real-Time Grasp Detection Using Convolutional Neural Networks (0) | 2018.11.13 |
|---|---|
| Use case (0) | 2018.11.13 |


